Merhaba,
Elasticsearch’ün hem setup exe’si hem de zip içinde çalıştırılabilir hali var. İlk başta setup olanla başlamıştım ama sonradan zip’li ile devam ettim. Aslında bu arkadaş Linux üzerinde çalışacak diye daha çok düşünülmüş sanki. O yüzden kara ekranlarda çalıştırılmasına alışmak daha faydalı diye böyle bir tercihte bulundum. Yarın bir gün bunu Ubuntu üzerinde çalıştıracağız muhtemelen.
Elasticsearch tarafına C#’tan erişmek için kullanacağımız NEST kütüphanesi ben bu satırları yazarken 6’yı destekliyordu. 7’de JSON serialize hatası veriyordu. Mecburen 6’ya döndüm.
6 ve 7 arasında da index oluştururken söz dizimi farkları var.
Misal birisinde mappings kısmında tür belirtmek lazım, diğerinde yok gibi.

Windows makinası için JAVA JDK’yı indirip kurmakta fayda var.
Kurduktan sonra da aşağıdaki ayarları yapmalıyız:
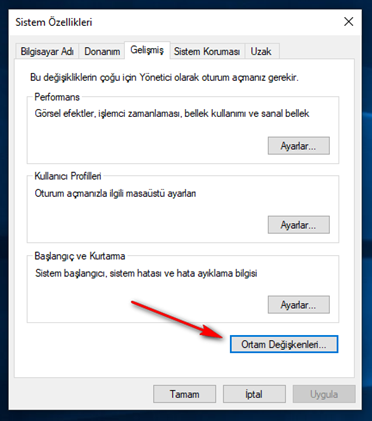
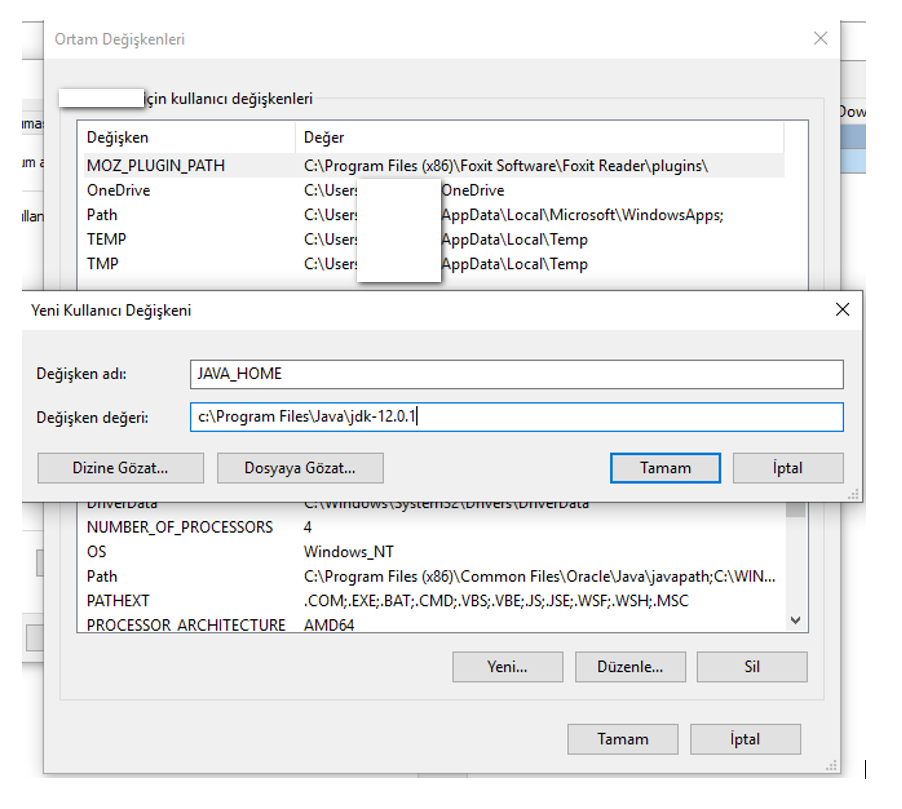
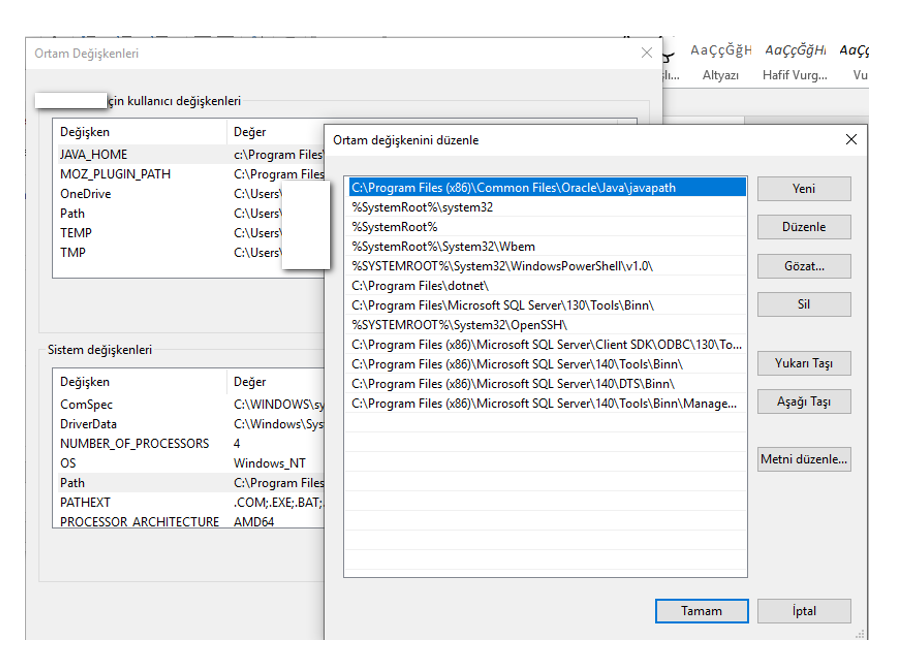
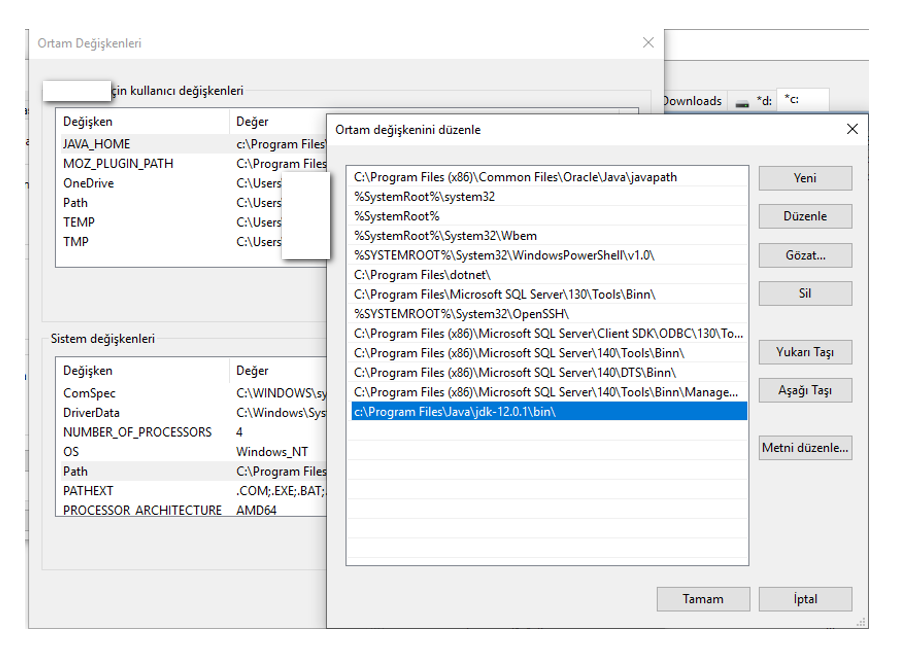
Zip dosyasını indirip açıyoruz ve aşağıdaki CONFIG dizin altındaki ayarları yapıyoruz.
….\config\elasticsearch.yml
dosyasını açıp aşağıdaki hareketleri yapmak gerekiyor:
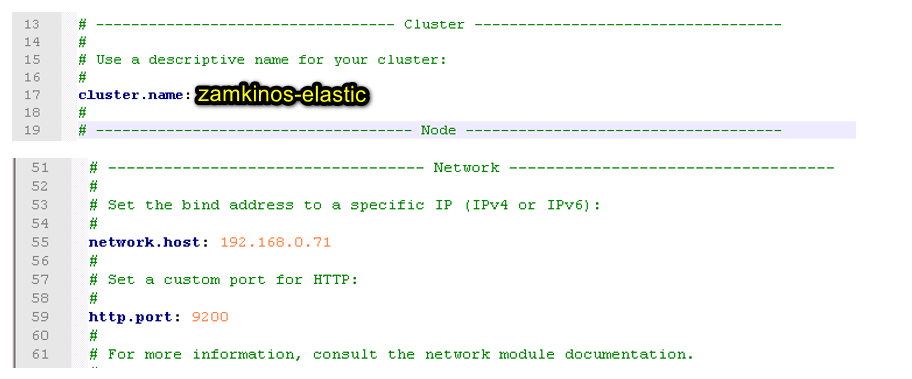
Aslında elasticsearch’in kurulu olduğu makinada ona erişecek olan WebApi’de bulunsa ve sadee localhost’tan hizmet verse sanki en temizi bu gibi.
Sonrasında bin dizini altındaki elasticsearch exe sini komut satırından çalıştırmak yeterli.
CMD’yi yönetici olarak başlatmak lazım.
Açılışta could not load…. vs tarzı satırlar varsa gene config altında jvm.options dosyasının en altına;
-Duser.language=en
satırını eklemek lazım.
- Bir de gene JVM dosyasında –Xms1g ve –Xmx1g olan maksimum ve minimum heap boyutları var. Ben bunları 2 yaptım.
Genelde çıkan hataları GOOGLE’da aratarak çözüm bulunabiliyor, yılmamak lazım. Başka versiyonlarda başka hatalar çıkabilir. Bendeki 7.1.1 versiyonu idi. (Sonra 6.8’e geçmek zorunda kaldım .net NEST kütüphanesi yüzünden)
Klasik veritabanı ile Elastik tarafındaki kavramların karşılıkları aşağıdaki şekilde:
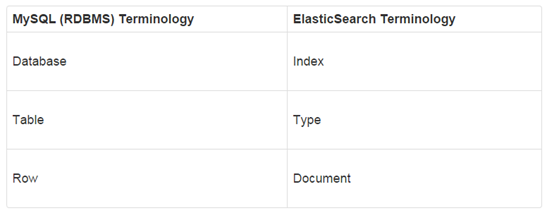
Aslında database = index değil de, elastic tarafında cluster oluyor.
SQL’deki Table kavramı, elastic tarafında index kavramına yakın.
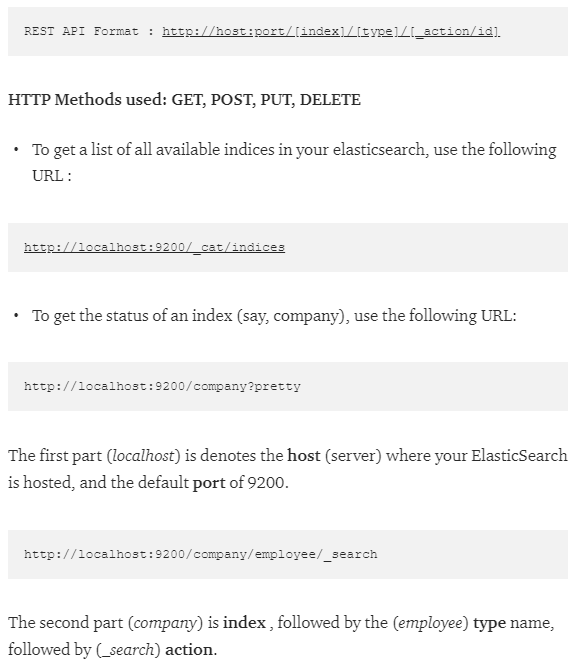
Sonrasında tarayıcıdan aşağıdaki şekilde çağırabiliyoruz:
http://localhost:9200/_cat/indices?v
komutu ile tüm indeksleri görüntüleyebilirsiniz.
elasticsearch ile birlikte logları görüntülemek ve yönetmek için Logstash ve Kibana’yı kurmak gerekiyor. İlerleyen zamanda inşallah oraya da geleceğiz…
Google Chrome’da “ElasticSearch Head” eklentisi ile index, shard,..vs yönetmek biraz daha kolaylaşıyor.
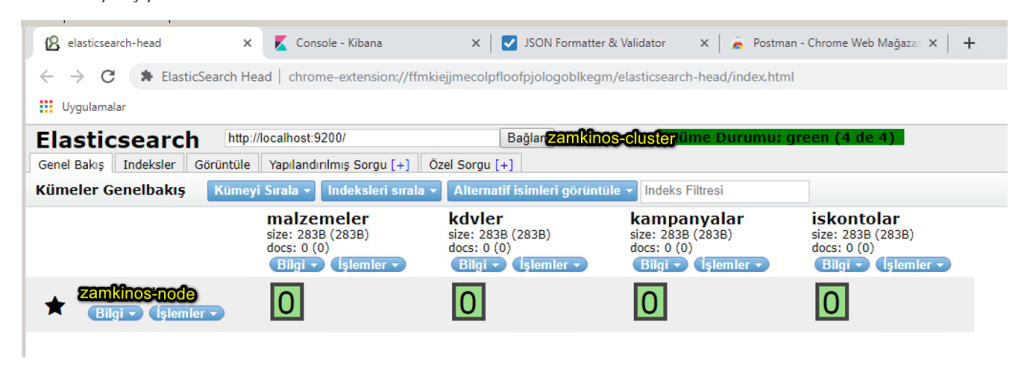
Dokümanın sonunda ekran görüntülerini attığım makalelerde güzelce anlatmış arkadaşlar. Kilit noktaları belirtmekte fayda var.
- Canlı ortam kümesi(cluster) en az 3 node içermeli diyor uzmanlar. Ayrıca bu nodlar tek sayı olmalı diyor gene bu arkadaşlar.
- ElasticSearch Lucene olarak adlandırılan bir arama motoru kullanıyor altyapı olarak.
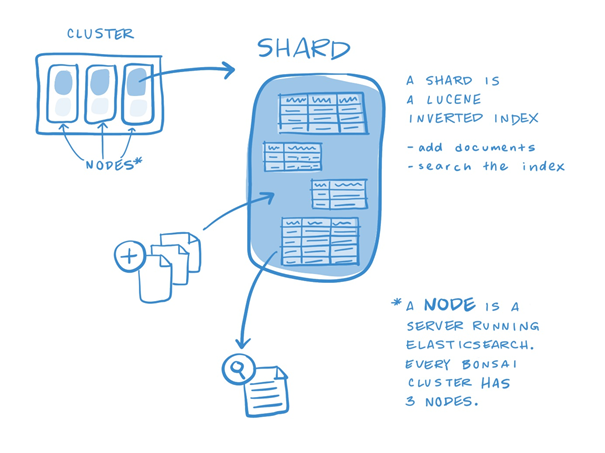
- Shard ve Replica kavramları var. Lucene üzerine kurulu bir sistem Elastisearch. Shard kelime anlamı olarak “kırık parça” gibi manaya geliyor. Kırık çömlek, bardak parçaları gibi. Bu parçaların her birinin bir Lucene örneği (instance) olduğunu ifade etmiş arkadaşlar.
- Replica ise bu Primary Shard yapısının yedeği. Primary kısmında bir bozukluk olursa burası devreye giriyormuş.
- Yeni bir indeks oluştururken bunların ideal adetleri nedir sorusuna da ihtiyacınızı doğru ölçümleyip karar vermeniz lazım diyorlar. Aslında bir görüş de defaut değerler neyse ona göre başla, sonra yetmezse zaten bakarsın şeklinde. Ben de bu görüşü savunuyorum. Shard 1 yaptım ve replika 1 değil 0 yaptım. Bunlar node ve replikaları hep farklı makinalarda duracak şekilde tasarlamışlar anladığım kadarıyla. Yani aynı makinada olduktan sonra çok da bir avantajı yok gibi görünüyor. Biri patlarsa öbürü devam etsin ya da yükü dengelesin mantığı daha çok farklı makinalarda olması durumunda geçerli diye düşünüyorum.
- İndex yapısının grafiksel görünümü aşağıdaki şekilde.
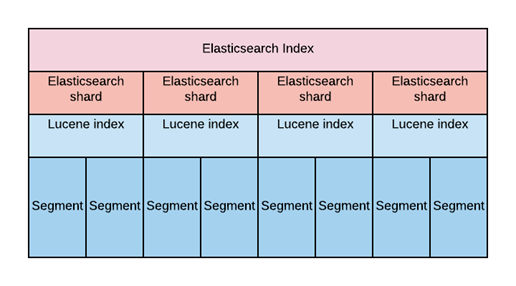
- Index ismi tanımlarken sınırlamalar var. Genelde herhangi bir programlama dilinde de olan kısıtlamalar. En mühimi tüm harflerin küçük harf olmak zorunda olması.
- Alan tanımlarında “string” ifadeler için “keyword” ve “text” tipleri var. “keyword” tipini “=” ile arayacaklarımız, “text” tipini ‘like’ ile arayacaklarımız gibi düşünebiliriz.
- Elasticsearch ve kibana kullanacaksak ikisinin de aynı versiyon olmasında fayda var sanki. Aralarında uyumsuzluklar olabiliyor. Garantici yaklaşım ikisini de aynısı olması.
- Bu ikisini ayağa kaldırmak biraz uğraştırabilir. Çünkü arkadaşlar versiyonlar arasında ciddi değişiklikler yapmışlar.
- Misal 7.1’de yml dosyası ProgramData’nın altında.
- Kibana’ya sadece index oluşturmak için ihtiyacımız yok gibi. Herhangi bir WebApi tetikleyicisi ile de mümkün. Aşağıda örneği mevcut.
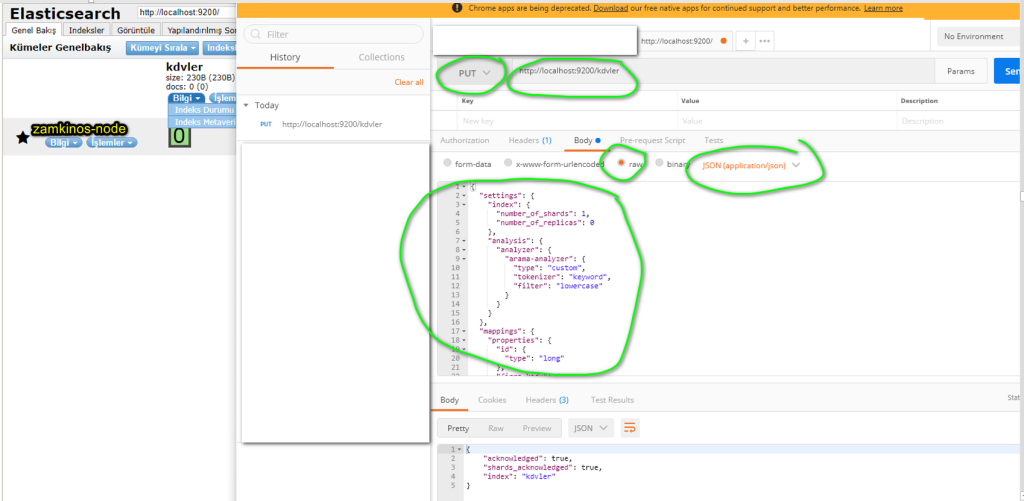
- Kibana’yı kullanarak index oluşturmak için de aşağıdaki şekilde ilerlemek gerekiyor.
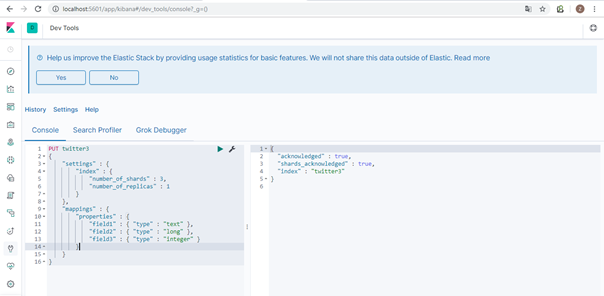
PUT kdvler
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"analysis": {
"analyzer": {
"arama-analyzer": {
"type": "custom",
"tokenizer": "keyword",
"filter": "lowercase"
}
}
}
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"firma_kodu": {
"type": "keyword"
},
"kaynak_ulke_kodu": {
"type": "keyword"
},
"hedef_ulke_kodu": {
"type": "keyword"
},
"malzeme_kdv": {
"type": "keyword"
},
"musteri_kdv": {
"type": "keyword"
},
"kdv_tutari": {
"type": "float"
},
"olusturma_tarihi": {
"type": "date"
}
}
}
}





Selamlar.